A follow-up to yesterday’s post on rotating two Claude accounts. The switcher worked fine at first, then one morning both credentials were dead with an invalid_grant error. Fixing it once was easy. Fixing it properly — so it stays fixed while Claude CLI, MCP servers, IDE extensions, and stray tmux panes all silently rotate tokens behind your back — took the rest of the week and turned the switcher into something more like a credential warden.
The Problem
The switcher worked fine through that first day. I rotated between two accounts several times, everything responsive and smooth.
The next morning, I tapped switch and got an invalid_grant error from the refresh endpoint. Both accounts. Nothing had changed on my end: no re-login, no config touches, no upgrades. The credentials that worked last night were simply dead.
I re-logged in to unblock my day, but “it works until it doesn’t, and the fix is re-login” is exactly the friction I built the switcher to eliminate. So I went back in to figure out what was happening.
How Credential Rotation Works
Claude uses OAuth 2.0 where refresh tokens are single-use and rotate on every refresh. This is standard practice.
Your CLI stores { accessToken, refreshToken, expiresAt }. The access token is short-lived (about an hour). When it’s near expiry, the CLI POSTs the refresh token to the token endpoint and gets back a new pair: new access token and new refresh token. The old refresh token is revoked server-side immediately.
Now consider the setup I built. Each account has a .cred snapshot on disk, my stored copy of its { accessToken, refreshToken, expiresAt }. When I switch from account A to account B, I install B’s tokens into the Keychain; A’s snapshot stays on disk, unchanged.
Between switches, multiple claude processes may be running against the Keychain: an MCP server, a VS Code extension, maybe a tmux pane I forgot about. When one of them refreshes account B’s token in the background, the refreshToken in my on-disk snapshot for B now points to a credential that’s been revoked. I don’t find out until the next time I run use secondary and the refresh fails with invalid_grant.
The failure mode is cache drift: my disk snapshot and the server’s view of which refresh-token lineage is alive have diverged. The tokens I saved got rotated out from under me by a background process I didn’t track.
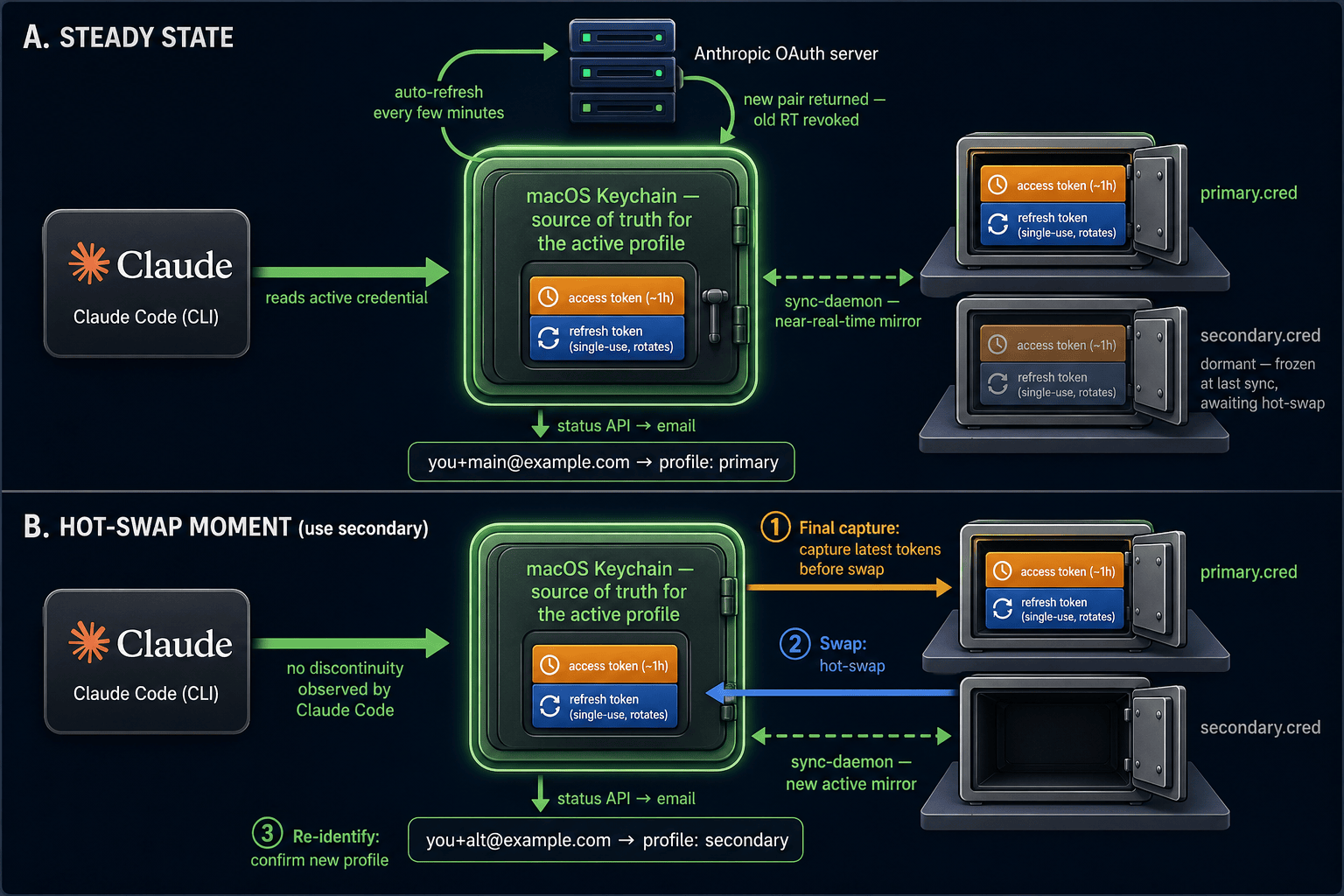
Steady state (top): the live credential rotates against Anthropic's server every few minutes; the sync-daemon mirrors each rotation back to the active profile's .cred on disk. Hot-swap (bottom): on use secondary, capture the latest tokens to disk, swap the dormant .cred into the Keychain, re-identify by email — Claude Code observes no discontinuity.
Correcting Assumptions
I also looked at the reverse-engineered Claude Code mirror at yasasbanukaofficial/claude-code and found a few assumptions I had gotten wrong. Nothing critical, but worth adapting to what the actual source uses.
I was hitting console.anthropic.com/v1/oauth/token instead of platform.claude.com/v1/oauth/token. Different authorization servers with different rate limits. I was also refreshing at 2-minute expiry skew instead of the upstream 5-minute window, and omitting the scope field from refresh requests (which is technically legal but different endpoints enforce it differently). None of these would have broken things entirely, but matching the actual source made the implementation cleaner.
Reactive Refresh for In-Flight Drift
Those three fixes reduced the drift. They didn’t eliminate it. No amount of proactive refresh saves you from the case where another claude process rotated your refresh token between your last save and now. The token on disk is dead, you just don’t know it yet.
For that, I added a reactive path: when the live “is this access token still good” check against api.anthropic.com/api/oauth/account returns 401 or 403, attempt one refresh, then retry validation. Nine times out of ten, the access token is dead but the refresh token is still alive, the retry yields a fresh pair, and the user sees a use <alias> that “just works.”
A small aside on why we validate against api/oauth/account and not claude /status: the CLI’s status command reads ~/.claude.json, which is a cache it writes itself. If the Keychain entry was swapped out underneath it, the JSON file is stale and claude /status will happily report the old account as still-authenticated. The only source of truth is the server — round-tripping the token to api/oauth/account and reading back the email field.
What Reactive Can’t Save You From
Reactive refresh handles one specific case: access token dead, refresh token still alive. The tenth time — when the refresh token itself has been rotated out — you can’t reactive your way out of it. A dead RT gives invalid_grant both proactively and reactively.
Once I started cataloguing the other ways the RT could die, the list was longer than I’d assumed:
- Background rotation by a sibling claude process. MCP server, IDE extension, a tmux pane ticking over. Any of them can call the token endpoint and consume my saved RT. The original overnight failure.
- Manual
claude /logout && claude /logininto a different account. The currently-active profile’s RT is now on a lineage that’s been revoked; its.credon disk is dead. You discover this the next time you try to switch back. - Two claude processes racing on refresh. First-to-rotate wins; the second holds an in-memory RT that no longer exists server-side. Both started with the same token; only one survives the race.
- The alias just aged out. Anthropic’s RT lifetime is ~7 days. Don’t touch a profile for eight days and its stored RT is stale on age alone.
Reactive refresh covers case 1 when the access token is the only thing dead. Cases 2-4 need structural fixes, not retries.
The Safer Login Dance: rotate
Case 2 was the one biting me the most. Any time I wanted to log in a fresh account, I reached for claude /logout && claude /login reflexively — and every time, that stranded whatever was currently active.
So I added a rotate <alias> command that owns the whole logout-login-register cycle. The shape is: save and back up the active profile’s tokens first, wipe the Keychain so no stray process can rotate them during the gap, guide you through logging in as the new account, and register on confirm or roll back to the frozen state on cancel. It’s ceremonial, but when the CLI itself runs out-of-process, ceremony is the only way to make this operation atomic.
rotate is the supported complement to use: use moves between already-registered aliases, rotate introduces a new one (or refreshes a stale one) without stranding the active one. I also taught add to detect external log-out-and-back-in and warn before clobbering anything, pointing at rotate as the safer flow.
Continuous Sync: Treating the Dashboard as a Warden
The structural fix for cases 1 and 3 was to stop treating the disk snapshot as a frozen-at-register copy and start treating it as a trailing-but-near-live mirror of the Keychain (panel A in the diagram above).
The dashboard was already polling Claude usage every couple minutes. Cheap addition: on every successful poll, snapshot the live Keychain blob back to the active profile’s .cred. Gated by an identity check — because the right “should I save this rotation?” question is not “did the token change?” (background rotations are normal and we want to capture those) but “is this still the same account?”. The former lets silent drift through; the latter is the invariant actually worth defending.
With that running, the stored .cred for the active profile is always close to whatever the Keychain currently holds. By the time I run use <other>, the outgoing alias is effectively synced for free. The sync-daemon step inside use is now a belt-and-suspenders fallback for when the dashboard hasn’t been running.
The switch itself is a hot-swap (panel B): capture the active profile’s latest tokens to disk, install the target profile’s tokens into the Keychain, re-identify by email. Claude Code is reading the Keychain on each call, so it observes no discontinuity — just a new credential the next time it looks.
Making Drift Visible
Silent drift is worse than loud drift, because you only find out when the switch fails. So the dashboard now publishes a staleness signal per profile, rendered as a small badge on the profile card. Active profile sitting green means the sync-daemon is healthy; inactive profile going yellow is a free hint to switch through it preemptively before its stored token ages out.
There was a smaller UI papercut I hadn’t even noticed: the usage cache has a throttle to keep us off the rate limit, and right after a switch it was serving the outgoing account’s usage back into the card for the next few minutes. Fixed with a forced refresh on switch plus optimistic rendering from the target profile’s saved cache — the card now matches reality from t=0 instead of lagging for a cycle.
What Changed
- Refresh now hits the right authorization server, at the right expiry skew, with the right scope claim — matching the upstream CLI.
- Reactive refresh retries once on 401/403 and uses the server’s identity endpoint as the source of truth rather than the CLI’s own status cache.
- The dashboard continuously syncs Keychain → active
.cred, gated by an identity check so drift can’t slip through silently. usedoes the same sync on the outgoing profile as a fallback for when the dashboard isn’t running.- New
rotatecommand owns the logout-login-register cycle safely, with rollback on cancel. addwarns when the Keychain identity has drifted away from the active profile.- Profile card shows a per-alias staleness badge so drift is visible before it bites.
- Post-switch cards no longer render the outgoing account’s cached usage during the reconcile poll.
Full mechanics are at docs/claude-account-switching.md.
What This Taught Me
Three things stick with me now.
First: managing multiple rotating-token credentials in a sidecar is not a protocol problem, it’s a synchronization problem. OAuth’s semantics are straightforward. The actual complexity is “how do I keep on-disk snapshots in lockstep with a Keychain that other processes are silently rotating the bytes of.” The answer turned out not to be a cleverer snapshot but a sync-daemon — the dashboard is now as much a credential warden as a status display.
Second: identity is the right equality check, not bytes. The wrong instinct is “save when the token changed.” The right instinct is “save every rotation of this account, loudly warn when the account itself changed out from under us.” Every time I reached for byte comparison, I was building a silent-drift failure into the system.
Third: having the source available, even as a reverse-engineered mirror, was a huge multiplier. It closed the loop from “something is wrong” to “here’s the exact constant I had wrong” in an hour, and when I later needed to understand why claude /status lied after a Keychain swap, the answer was right there in the mirror’s invalidateOAuthCacheIfDiskChanged.
I said in yesterday’s post that I’d rather own a switchboard than pay for a bigger meter. A switchboard only helps if I don’t get my wires crossed. It turns out keeping the wires uncrossed isn’t a one-time wiring job — it’s an ongoing watch.