A follow-up to last week’s post on rotating two Claude accounts. The switcher worked through the first day, then both credentials were dead by morning. Fixing it once was easy. Fixing it properly took the rest of the week, and most of that week was me letting the wrong loop keep running.
The wrong loop
I tapped switch the next morning and got invalid_grant from the refresh endpoint. Both accounts. No changes on my end, no re-login, no upgrades. Just dead.
I knew vaguely why this happens. Claude OAuth refresh tokens are single-use; they rotate on every refresh. Any other claude process (an MCP server, an IDE extension, a tmux pane I forgot about) that touches the Keychain while account B is active will rotate B’s RT past the copy I have on disk. Switch back to B later and I’m installing a tombstone.
The right fix is straightforward: keep the on-disk snapshot in lockstep with the Keychain that Claude keeps updating. The wrong fix, which I spent four days on, is everything else.
How vibe coding builds a cliff
I was vibe coding this with Claude. Each time the failure recurred, the next iteration shipped another sentry. A pre-swap identity check. A reactive refresh on 401/403. Per-lineage cooldowns when 429s started showing up. A per-alias refresh budget. An auto-quarantine when three lineages 429‘d in a window. A “needs recovery” badge on the profile card. A cooldowns CLI subcommand to list quarantines. A clear-quarantine command to override them.
To sharpen the iterations I fed the agent the reverse-engineered Claude Code mirror at yasasbanukaofficial/claude-code, so it could compare upstream’s OAuth client to mine line by line. Now the loop produced better harnesses. The diff between my refresh call and upstream’s grew a list of small corrections (wrong endpoint host, wrong refresh skew, missing scope field), each of which the agent shipped, and each of which made the system more elaborate without making the failures stop.
By day three the dashboard had grown about a thousand lines of guardrail code, the defenses doc had four named failure modes and a Phase 3 quarantine flowchart, and the switch was still failing.
Diving in
I took the agent off it and went looking myself. The log pattern was always the same: fresh login worked, the next few hours of switching worked, then 429 rate_limit_error from the refresh endpoint, persistent, on every lineage, no Retry-After header, only ever from my code path. Claude Code’s own background refreshes never tripped it.
So I formed a hypothesis: the edge wasn’t rate-limiting the token, it was rate-limiting the caller. Same token, same body, same endpoint, request envelope changed:
$ curl -H 'Content-Type: application/json' \
-d "$BODY" https://platform.claude.com/v1/oauth/token
HTTP/2 429
{"error": "rate_limit_error", ...}
$ curl -H 'Content-Type: application/json' \
-H 'Accept: application/json, text/plain, */*' \
-H 'User-Agent: axios/1.7.7' \
-d "$BODY" https://platform.claude.com/v1/oauth/token
HTTP/2 200
{"access_token": "...", ...}
Two header lines of difference, 429 to 200. Anthropic’s edge fingerprints OAuth requests by client; bare curl/* gets bucketed as untrusted. I shipped the spoof and called it done.
The 200 was a lie
It held for almost a day. Then I switched back to an account I hadn’t touched since morning, opened Claude Code, and saw my 5-hour quota at 100%. I’d been on the other account all day. claude /usage confirmed it. I logged out and back in through Claude Code itself; the meter immediately reset to 0%.
The 200 was technically correct: real token, valid JSON, parsed without complaint. But the bucket Anthropic put it in was tagged untrusted, and the meter Claude Code read for that account was the untrusted-bucket meter, pinned at the cap. The 429 had been the cheaper signal that the edge didn’t recognize my client. The maxed-out quota was the more expensive signal. Both were saying the same thing: minting tokens from outside the allowlisted client doesn’t actually work.
Don’t refresh at all
The only reason my dashboard ever called the refresh endpoint was to pre-validate a dormant profile’s tokens before installing them. If I just install the dormant tokens as-is and let Claude Code refresh on its first API call, the whole class of problem disappears. The refresh endpoint is not the dashboard’s to call.
So the dashboard stopped calling it. The pre-swap identity check is now best-effort: try /api/oauth/account with whatever access token is in the blob, use the live response if the AT is fresh enough, and fall back to the byte-level email embedded in the blob plus the cached account UUID pin if it returns 401/403. Either way the swap completes, Claude Code refreshes through its own allowlisted path on first use, and the credential lands in a clean attribution bucket.
The other half of the fix was the piece I should have been investing in all week: a continuous mirror of the active Keychain entry to the on-disk .cred, gated by an identity check, running on every usage poll. With that running, the dormant .cred is always close to whatever Claude Code most recently rotated into the Keychain, and the switch is just a hot exchange of bytes.
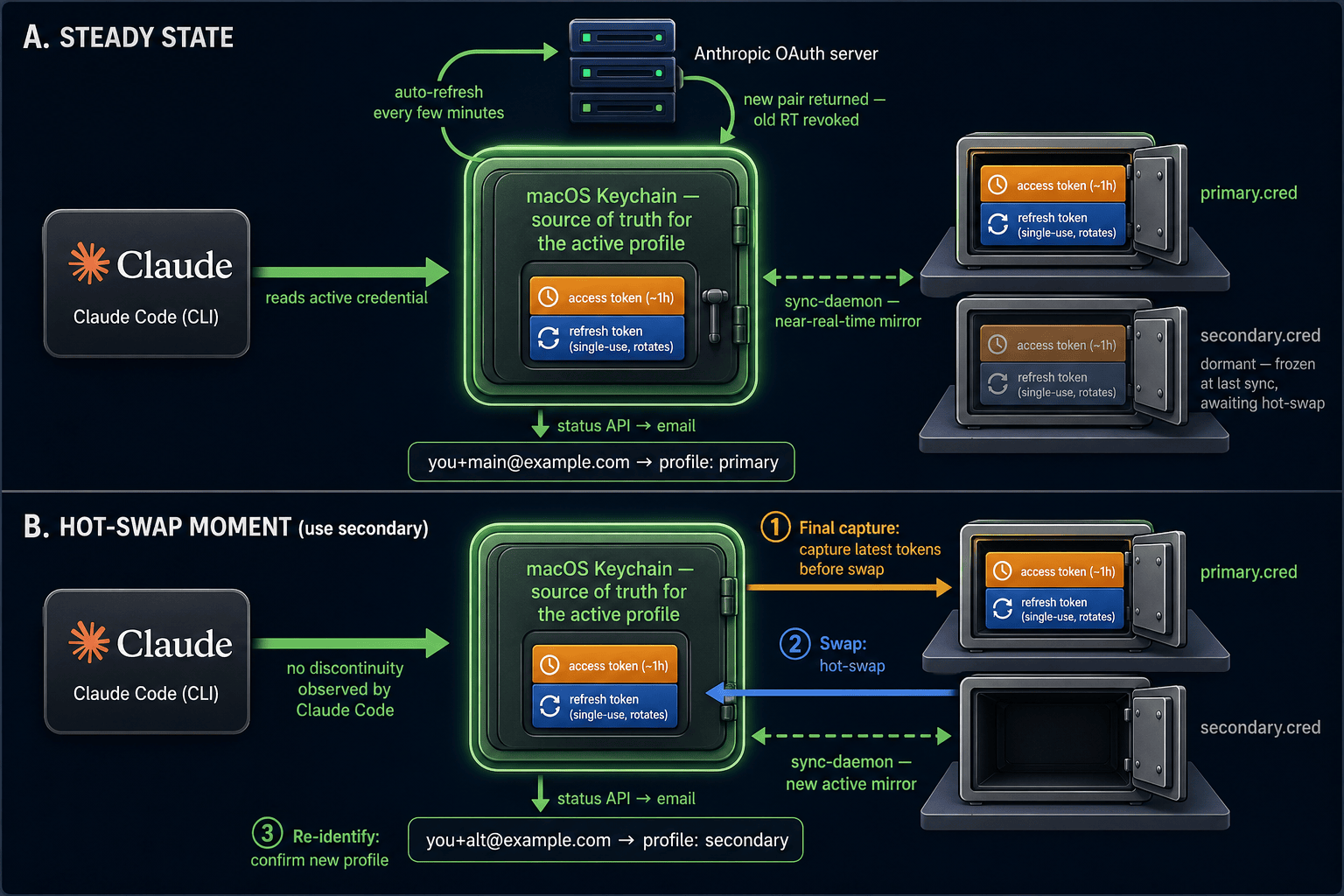
Stage 1: Normal operation with sync-daemon continuously mirroring the active Keychain credential to disk. Stage 2: On use secondary, capture the latest tokens from the current Keychain entry to the outgoing profile's .cred. Stage 3: Select the new profile and prepare to swap. Stage 4: Install the new profile into the Keychain; Claude Code reads the fresh credential on its next API call with no discontinuity.
Removing the refresh call took about sixteen hundred lines out of the repo: the refresh function and its retry choreography, per-lineage cooldowns, per-alias quarantines, the “needs recovery” UI badge, the cooldowns and clear-quarantine CLI subcommands, and the runbook docs that all of it required. Every line was a defense against a class of failure the dashboard no longer creates.
What I take away
When a misbehaving system is one you’re building with an agent that’s eager to add layers, the instinct is to keep adding layers. Each layer fixes a specific log line. None of them fix the misframing.
The misframing here was easy to miss because the agent was so productive inside it. The first refresh call had to happen on my side because the switcher needed to “validate” a dormant credential. From that one premise the agent extruded a whole runbook: cooldowns to handle the 429s, budgets to handle the cooldowns, quarantines to handle the budgets, recovery commands to handle the quarantines. Every iteration shipped, every iteration was internally consistent, every iteration made the failure mode harder to see.
The actual fix was to delete the premise. Once I stopped calling that endpoint, the rest fell out of the codebase by itself.
A 200 is a guarantee that the surface contract was met. It is not a guarantee the resulting state is healthy. The honest fix wasn’t a better spoof; it was admitting I shouldn’t have been calling that endpoint at all.
I said in last week’s post that I’d rather own a switchboard than pay for a bigger meter. A switchboard only helps if I don’t get my wires crossed. It turns out keeping the wires uncrossed isn’t even a wiring job; it’s a discipline about which wires are actually mine to touch.